

Model
- KEDA operator (
platform/keda, nskeda, auto-sync): controller only, no cost. - ScaledObject
raw-vllm(serving/raw-vllm/scaledobject.yaml, nsserving) scales the vLLM Deployment onsum(vllm:num_requests_waiting)(threshold ~5/replica) + a KV-cache secondary. Ships paused. While paused KEDA touches no replicas, somake vllm-up/downand $0-idle are unaffected. Un-pause only for a deliberate load test, then re-pause.
/spec/replicas. An unpaused minReplicaCount: 1 keeps a GPU node up
24/7 (~$240/mo) and overrides make vllm-down: that is why it is paused by default. Never leave
it un-paused on the GPU tier.
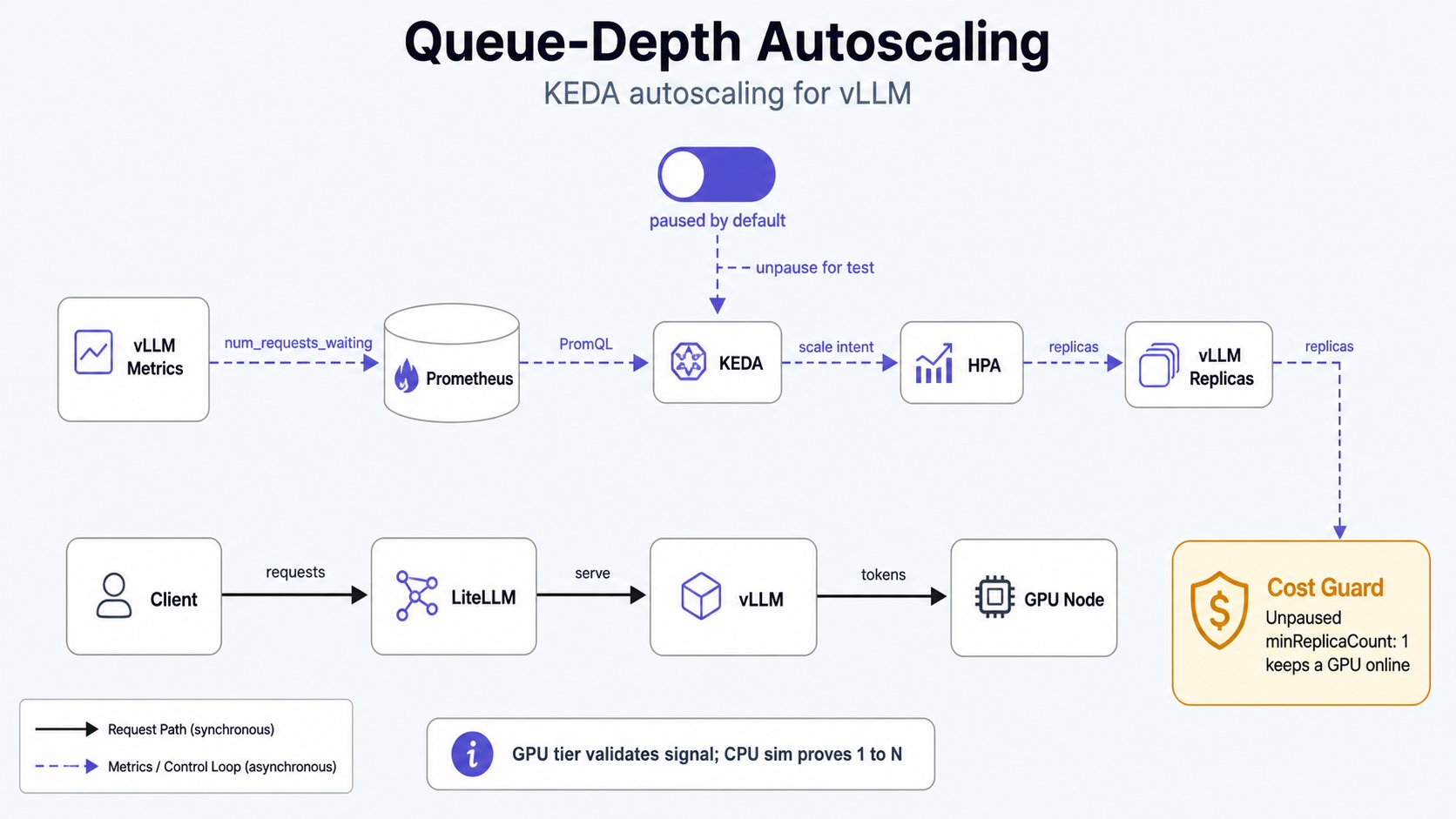
1. Toggle the autoscaler
autoscaling.keda.sh/paused annotation live. The app is manual-sync, so selfHeal
will not revert the toggle; a manual argocd sync reapplies the committed default (paused: true),
the safe state, so that is fine.
2. GPU-tier load test (validates the trigger; single-GPU caps scale-out at 1)
GPUS_ALL_REGIONS=1 caps the GPU pool at one node, so real raw-vllm cannot exceed 1 replica.
Use this to confirm KEDA reads the metric and computes scale intent; prove 1→N on the sim (§3).
<unknown> for TARGETS, KEDA cannot read the metric; see §4.
3. Free CPU-sim scale-out proof (1→N, $0 GPU)
Thellm-d-inference-sim backends (ns inference, no GPU) emit the same
vllm:num_requests_waiting. Scrape them into Prometheus and point a throwaway ScaledObject at them
to demonstrate genuine 1→N without GPU cost. These are validation aids: apply on demand, delete
after (not committed manifests).
4. Troubleshooting
HPA TARGETS<unknown> / ScaledObject READY=False. KEDA can’t reach Prometheus or the query
returns no series.
- Confirm the Prometheus service name:
kubectl -n monitoring get svc | grep prometheus. The ScaledObject points atprometheus-operated.monitoring.svc:9090(the operator’s stable headless service). If your kube-prometheus-stack release exposes a different service, updateserverAddress. - Confirm the metric exists and the name is right (vLLM V1 renamed several series):
kubectl -n serving port-forward deploy/raw-vllm 8000 & curl -s localhost:8000/metrics | grep -E 'num_requests_waiting|cache_usage'. Expectvllm:num_requests_waitingandvllm:kv_cache_usage_perc(NOTgpu_cache_usage_perc). Fix thequeryinscaledobject.yamlif a name differs.
cooldownPeriod is 300s (5 min) by design to avoid flapping on a
slow-cold-start workload; wait it out.
It won’t stop bringing the GPU up. You left it un-paused. make keda-demo-down then
make vllm-down. The committed default is paused.
See also: vllm-serving.md (the replicas/ignoreDifferences interaction), staged-bring-up.md.