

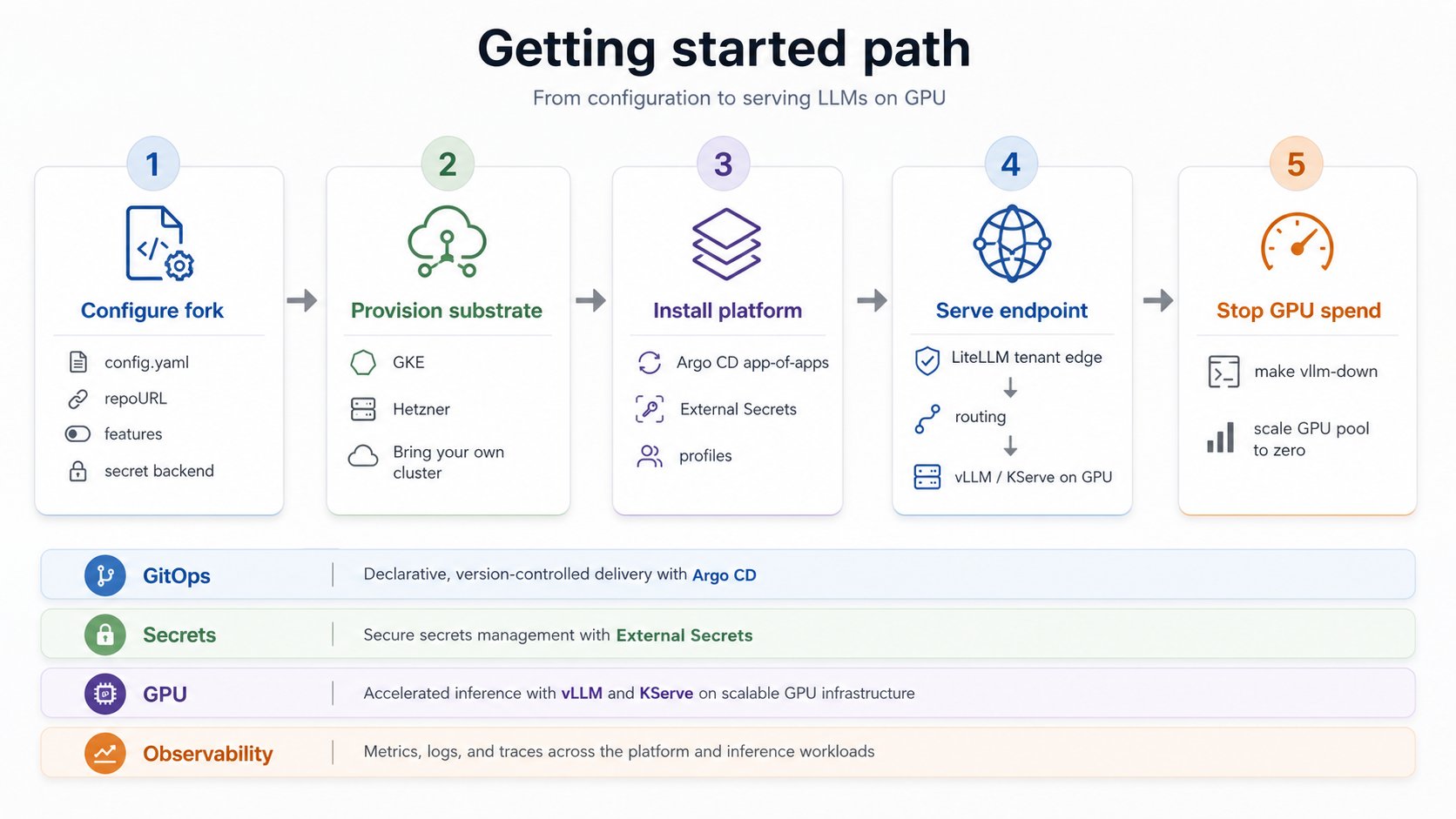
Configure
Fork the repo and set non-secret values in one
config.yaml. This step is cloud-independent.Provision infrastructure
Stand up a Kubernetes cluster with GPU nodes. This is the cloud-specific step: pick GKE, Hetzner,
or bring your own cluster.
Why the split
The substrate (cluster, node pools, identity, IAM, GPU drivers) is the part that changes between providers. The in-cluster stack (GitOps delivery, serving, routing, tenancy, observability) does not. Keeping infrastructure provisioning separate from platform installation is what makes the platform portable: to move clouds you re-solve the substrate, not the platform. The one substrate detail that leaks into the platform is the GPU stack. On GKE the managed node image ships the NVIDIA driver, device plugin, and DCGM. Off GKE you run the NVIDIA GPU Operator yourself to provide the same three things. The serving layer above it is unchanged. This is called out where it matters in Provision infrastructure and Install the platform.What you end up with
A working, authenticated, OpenAI-compatible vLLM endpoint servingQwen/Qwen2.5-0.5B-Instruct on a GPU, with Argo CD reconciling the stack from your fork, and
secrets materialized keylessly from your cloud’s secret manager. The GPU is scale-to-zero, so
the expensive part costs nothing when idle.
Cost (GKE reference). Idle baseline is ~0 until a GPU pod schedules) and an L4 runs at roughly $0.70/hr on-demand. Never leave a GPU running; the teardown step in Install the platform scales it back to zero in one command.