

Stack in one picture
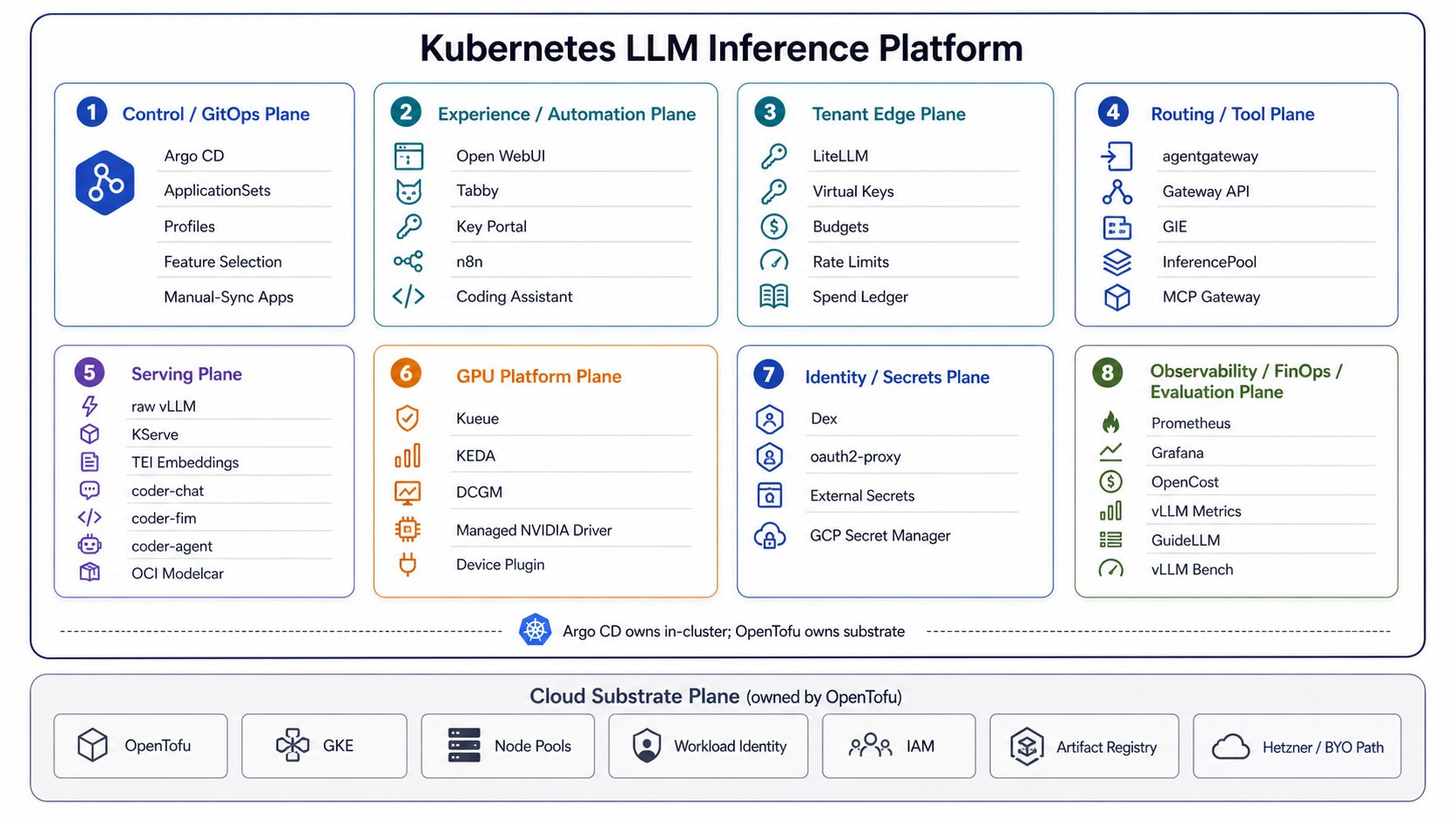
What it proves
| Proof point | Where to look |
|---|---|
| vLLM and KServe can serve the same OpenAI-compatible model path. | Serving layers compared |
LiteLLM owns tenant keys, budgets, spend, and the public /v1 facade. | LiteLLM guide |
| Gateway API plus GIE routes by inference signals instead of plain HTTP load balancing. | Inference gateway guide |
| Kueue and KEDA keep GPU admission, quota, and queue-depth autoscaling explicit. | GPU debugging guide |
| Benchmarks tie latency, throughput, GPU use, and KV-cache pressure to the same run. | Benchmark results |
Why it exists
Self-hosting LLM inference well is not “run vLLM in a pod.” A production endpoint has to solve GPU scheduling and quota, inference-aware routing, per-tenant keys and budgets, keyless secrets, scale-to-zero economics, model delivery, and observability. It also has to stay portable instead of welding itself to one cloud’s managed services. Each of those is a decision, and most reference setups either skip them or hard-code them to a single provider.Operating model
The platform packages the open-source control plane behind one forkable repo: vLLM, KServe, Gateway API with the Gateway Inference Extension, Kueue, KEDA, LiteLLM, External Secrets, and Argo CD. A hard line separates two halves: Substrate is the cluster, node pools, identity, and GPU drivers. Infrastructure-as-code owns it, and it is swapped per cloud. Platform is everything inside Kubernetes. GitOps owns it, and it stays identical across clouds. That separation is the portability story. A platform you can fork and run on any GPU-capable Kubernetes cluster: GKE today, with Hetzner and bring-your-own cluster paths documented. It scales from a single scale-to-zero L4 to a multi-tenant, highly available deployment without changing the in-cluster architecture.Start by intent
| Intent | Start here |
|---|---|
| See the system boundary and request path. | Architecture |
| Bring up a fork from zero. | Get started |
| Operate a running stack. | Guides |
| Check measured serving behavior. | Benchmark results |
| Look up terms, targets, models, and secrets. | Reference |
| Understand why the stack is shaped this way. | Design rationale |