

make vllm-up/down, the KServe idle-pause):
- Deployment profiles (which layers):
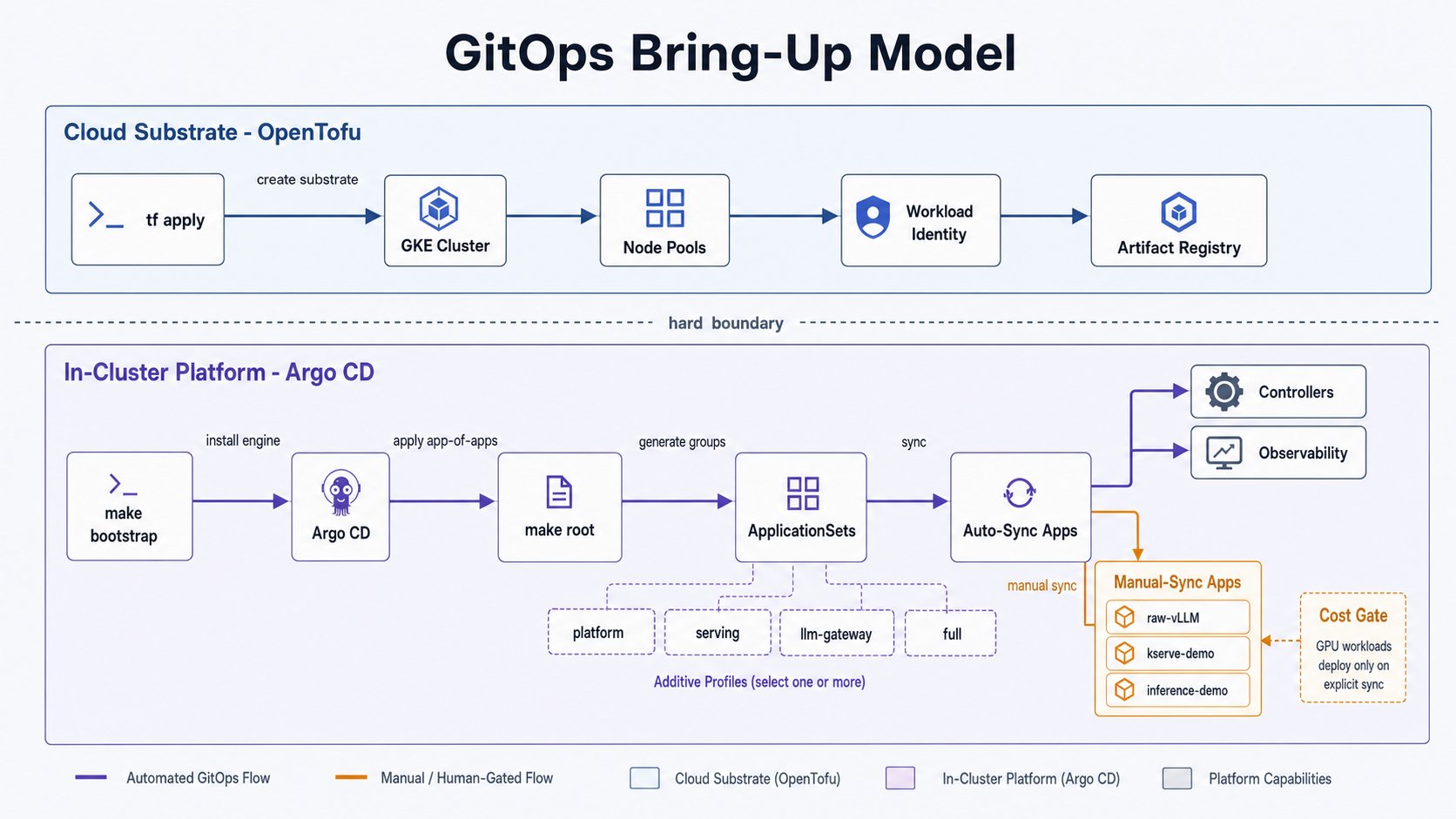
make root PROFILE=…applies the per-layer ApplicationSets inclusters/ai-dev/appsets/(additive:platform⊂serving⊂llm-gateway⊂full, wherefulladds theexperienceanddemoslayers). The per-group catalog lives underclusters/<env>/catalog/. Capability selection (which groups within a layer) is config-driven: editconfig.yamlfeatures:, runmake resolve-groups, thenmake root; disabling a group prunes it. - Sync policy (which workloads deploy): within whatever profile, most apps are auto-sync;
the paid/heavy workload apps are manual-sync, created as
Applicationobjects onmake rootbut not deployed until an explicit sync. This is the cost gate: the GPU node and the model pods only exist when you bring them up.
| Manual-sync app | Layer | Why manual |
|---|---|---|
raw-vllm | serving | GPU cost; make vllm-up/down owns replicas |
coder-chat, coder-fim, coder-agent | serving | GPU cost; coding-assistant models, brought up with argocd app sync |
kserve-demo | demos | CPU ISVC, forces a 2nd node; paused when idle |
inference-demo | demos | sim routing demo, brought up deliberately |
n8n | experience | workflow surface; its own key-minter Job, brought up deliberately |
Bring-up order
- Platform:
make root(defaultPROFILE=platform) applies theplatformAppProject + the platform root; auto-sync apps reconcile by sync-wave (CRDs/operators → controllers → config/observability). Widen the profile as you go (make root PROFILE=serving|llm-gateway|full). Wait for apps Healthy: - GPU smoke gate: needs the
servingprofile (make root PROFILE=serving) so theraw-vllmApplication exists. Bring serving up deliberately, prove the GPU path, then scale back to $0: - Demo / KServe: needs the
fullprofile (make root PROFILE=full) so the demos layer’s Applications exist. Sync on demand, tear down when idle:
Why manual (not just selfHeal off)
raw-vllmreplicas are scaled for cost;ignoreDifferenceson/spec/replicas+RespectIgnoreDifferenceskeep a sync from revertingmake vllm-up.kserve-demoidle-pause setsserving.kserve.io/stop=truelive; with auto-sync, selfHeal reverts it (the reason the annotation used to be baked into the manifest, now removed).- Manual sync also means a forker doesn’t pay for the GPU/model pods on first
make root.
argocd app set <app> --sync-policy none
is unnecessary here; they’re already manual, so just don’t sync them.