

security capability group. It turns two logical controls into enforced ones:
SR1 forces all model traffic through LiteLLM’s budget/key path, and SR2 stops GPU pods from
bypassing Kueue quota. Both are off by default: a single-tenant deployment never hits these gaps,
so they ship dormant and pull forward with multi-tenancy / governance.
Model
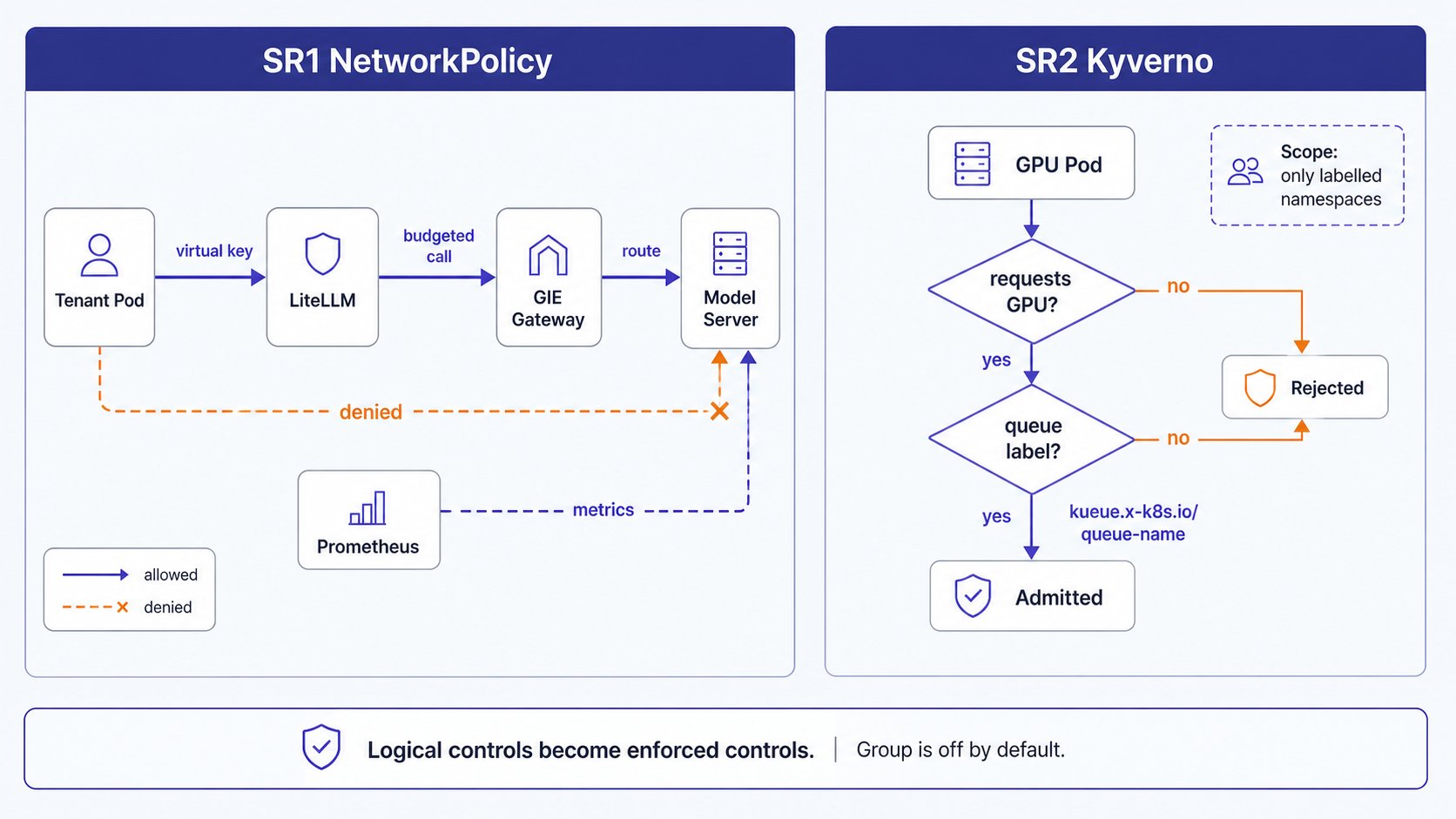
network-policies(SR1): nativenetworking.k8s.io/v1policies onservingandinference: a default-deny-ingress plus an allow-list. Onlylitellm,inference,agentgateway-system, andmonitoringmay reach the model servers + GIE gateway. Tenant namespaces can reach only LiteLLM, so virtual keys and budgets are no longer network-bypassable.kyverno(SR2): the Kyverno admission engine (Helm chart 3.8.1), nskyverno.kyverno-policies(SR2):ClusterPolicy require-kueue-queue-name: rejects any pod requestingnvidia.com/gputhat lacks thekueue.x-k8s.io/queue-namelabel, scoped to namespaces labelledllm-platform/kueue-managed=true. The platform’s own model servers (serving) are operator-managed and carry no queue-name, so they are deliberately out of scope.
datapath_provider = ADVANCED_DATAPATH,
set at cluster creation; retrofitting forces node recreation). Without it the policies are
authored-but-not-enforced.
1. Enable the group
group-security on its next reconcile. Argo’s repo-server
caches git revisions; after pushing, restart it (or wait the poll) so the appset reads the new
groups.generated.yaml, otherwise the group will not appear:
serving + llm-gateway layers to be applied (the policies target the serving and
inference namespaces); until they exist the NetworkPolicy apps selfHeal-retry.
2. Kyverno CRD install caveat
Kyverno’sclusterpolicies / policies CRDs exceed Argo CD’s client-side apply annotation limit
(256 KB), so a first sync can stall with metadata.annotations: Too long and the admission controller
crash-loops its sanity check (failed to check CRD clusterpolicies.kyverno.io is installed). The app
carries ServerSideApply=true; if Argo still applies client-side, bootstrap the CRDs once and pre-create
the namespace (avoids an RBAC-before-namespace race):
kyverno app; the admission controller passes its sanity check once the CRDs exist.
3. Validate SR1 (NetworkPolicy)
A pod outside the allow-list must be refused; a trusted-namespace pod must connect. Using theembeddings Service (port 80) in serving as the target:
monitoring is in the allow-list on purpose: Prometheus scrapes the model servers’ /metrics, so the
spend/serving dashboards keep working under the lockdown.
4. Validate SR2 (Kyverno admission)
Admission is evaluated at pod creation, so no GPU node is needed. Label a tenant namespace, then create GPU pods with and without the queue-name label:5. Bring a tenant namespace under SR2
Label it; unlabeled namespaces are untouched (the policy is opt-in per namespace):6. Disable
Setfeatures.security: false, make resolve-groups, commit + push. Argo prunes group-security
(NetworkPolicies, Kyverno, the ClusterPolicy) via the cascade finalizer.